
Stop repairing equipment only after it fails. This guide outlines a proactive maintenance strategy to boost efficiency and reduce costs. We’ll cover the technology, processes, and ROI drivers for modern manufacturing plants, giving you a clear playbook to shift from reactive repairs to predictive success and enhance your overall preventive maintenance strategy.
Learn more about powerful preventive maintenance features here
What is proactive maintenance?
Proactive maintenance is a strategy focused on anticipating and preventing equipment failures before they occur. It uses data analysis, predictive technologies, and condition monitoring to schedule maintenance tasks precisely when needed, optimising asset health and performance instead of reacting to breakdowns.
Why Proactive Maintenance Matters More Than Ever
In manufacturing, unplanned downtime is the enemy of profitability. A reactive "if it breaks, fix it" approach creates a cycle of emergency repairs, lost production, and escalating costs. This operational model directly damages key performance metrics and exposes the business to unnecessary risk.
Transitioning to a proactive maintenance framework addresses these core challenges by:
- Reducing Unplanned Downtime: A single hour of downtime can cost a plant thousands of pounds in lost revenue. Proactive methods can reduce unplanned outages by up to 50%, keeping production lines running smoothly.
- Improving Overall Equipment Effectiveness (OEE): OEE measures an asset's availability, performance, and quality. By preventing failures and optimising performance, proactive maintenance directly boosts all three components of your OEE score.
- Lowering Mean Time to Repair (MTTR): When maintenance is scheduled, technicians arrive with the right tools, parts, and instructions. This preparation significantly reduces the time needed to complete a repair, lowering MTTR and getting equipment back online sooner.
Proactive vs Reactive Maintenance: A Head-to-Head Comparison
The difference between these two strategies is fundamental. One plans for success, while the other reacts to failure. Understanding this distinction is the first step towards transforming your operations.
The Technology and Data Stack for Proactive Success
Effective proactive maintenance isn't about guesswork; it's about data. A modern programme integrates several key technologies to collect, analyse, and act on equipment health information.
- Sensors and the Industrial Internet of Things (IIoT): These are the eyes and ears of your operation. Vibration sensors, thermal cameras, acoustic monitors, and oil analysis tools collect real-time data on machine conditions. This IIoT network streams critical information about asset health.
- Computerised Maintenance Management System (CMMS): Your CMMS is the central hub for all maintenance activities. It manages work orders, schedules preventive tasks, tracks asset history, and organises parts stock. Integrating it with sensor data automates the creation of condition-based work orders.
- Analytics and Machine Learning: This is where the magic happens. Analytics platforms process the vast amounts of data from IIoT sensors to identify patterns and predict potential failures. Machine learning algorithms can learn an asset's normal operating profile and flag subtle deviations that signal an impending problem long before a human could detect it.
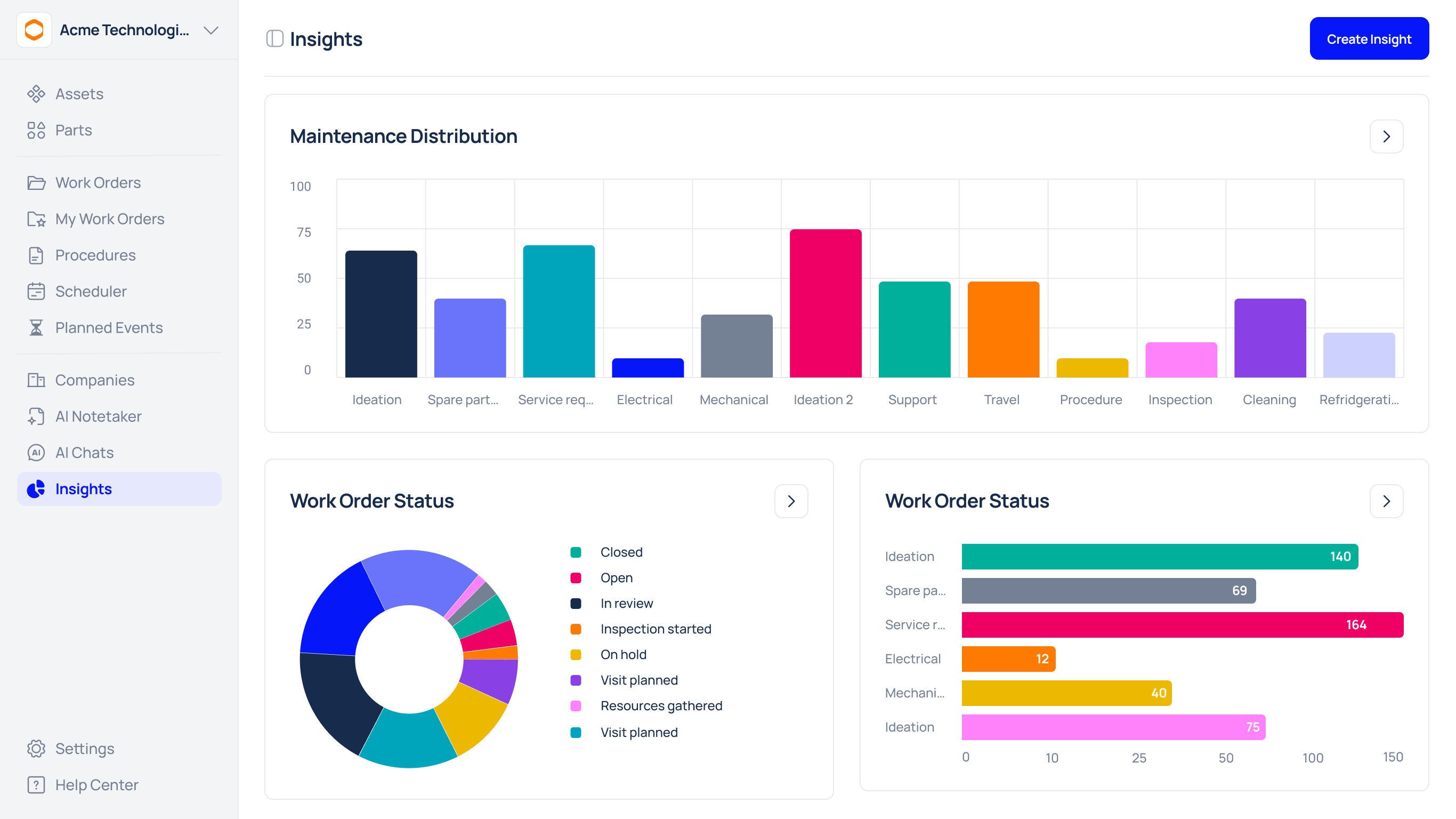
KPIs and Dashboards: Measuring What Matters
To manage your proactive maintenance programme, you need to measure its impact. A well-designed dashboard provides at-a-glance visibility into the health of your strategy and assets.
Key Performance Indicators (KPIs) to Track:
- Planned Maintenance Percentage (PMP): The percentage of maintenance hours spent on proactive tasks versus reactive ones. Aim for 80% or higher.
- Schedule Compliance: How well your team adheres to the planned maintenance schedule.
- Overall Equipment Effectiveness (OEE): The gold standard for measuring manufacturing productivity.
- Mean Time Between Failures (MTBF): A rising MTBF indicates your proactive efforts are successfully extending asset life.
- Maintenance Cost per Unit: Tracks the total maintenance cost relative to production output.
Your dashboard should visualise these KPIs with simple charts, allowing you to spot trends and make data-driven decisions quickly. For example, teams often use tools that help them create a pie chart for PMP and a line graph for MTBF, which can clearly illustrate how maintenance efforts are distributed and how performance improves over time.
Your 30-90-180 Day Proactive Maintenance Pilot Plan
Moving to a proactive model can seem daunting. The key is to start small with a pilot programme focused on a few critical assets. This approach allows you to show value, refine your process, and build momentum.
Top 3 steps to start a proactive programme:
- Select a Pilot Area: Choose 2–3 critical assets with a history of recurring failures. This provides a clear baseline for improvement.
- Define Your Tech Stack: Implement basic condition monitoring (such as vibration sensors) and ensure your CMMS can handle the data.
- Set Clear KPIs: Establish baseline metrics for downtime, OEE, and repair costs for your pilot assets to measure ROI.
Pilot Programme Timeline:
- Days 1–30: Foundation and Baseline
- Select Pilot Assets: Identify 2–3 assets that are critical to production and have a notable failure history.
- Form a Team: Assemble a cross-functional team including a maintenance technician, an operations lead, and an engineer.
- Establish Baselines: Document current downtime, repair costs, and OEE for the pilot assets.
- Install Sensors: Deploy basic condition monitoring sensors (e.g., vibration, temperature) on the selected equipment.
- Days 31–90: Data Collection and Analysis
- Collect Data: Let the sensors gather data to establish a normal operating baseline for each asset.
- Configure CMMS: Set up your CMMS to track work orders and data for the pilot assets.
- Set Alert Thresholds: Based on initial data and manufacturer specifications, define the condition thresholds that will trigger a maintenance alert.
- Train the Team: Educate the team on how to interpret alerts and respond with a planned work order.
- Days 91–180: Action and Evaluation
- Act on Alerts: When a condition alert is triggered, create a planned work order to inspect and service the asset before it fails.
- Track Performance: Continue to monitor KPIs. Compare post-implementation metrics against your initial baselines.
- Calculate ROI: Quantify the savings from avoided downtime and reduced repair costs. One company saved an estimated £200,000 annually on a single production line by preventing just three major failures.
- Build the Business Case: Use the pilot's success and clear ROI to justify a plant-wide rollout.
Vendor Selection Checklist
Choosing the right technology partners is crucial. Use this checklist to evaluate potential CMMS, IIoT, and analytics vendors.
Case Examples: Proactive Maintenance in Action
Seeing firsthand outcomes demonstrates the strength of this strategy. These examples show the tangible benefits of moving away from reactive maintenance.
Case Example 1: Automotive Parts Manufacturer
- Problem: Frequent, unplanned downtime on a critical CNC machine line was causing major production bottlenecks. Failures were costing an average of 8 hours of downtime per incident.
- Solution: They installed vibration and thermal sensors on the machines' main spindles. The data was fed into an analytics platform that predicted bearing failure weeks in advance.
- Outcome: The facility was able to schedule bearing replacement during planned shutdowns, eliminating unplanned downtime from this cause. This change increased the line's OEE by 15% and saved an estimated 100+ hours of lost production in the first year.
Case Example 2: Food and Beverage Plant
- Problem: A conveyor motor in the packaging area failed unpredictably, halting the entire line and leading to product spoilage. Reactive repairs were costly and time-consuming.
- Solution: A simple, cost-effective programme using handheld thermal imaging was introduced. Technicians performed weekly checks on all critical motors.
- Outcome: An overheating motor was identified during a routine check. The planned replacement took just two hours during a shift change, avoiding an estimated £25,000 in lost product and emergency repair costs. This simple preventive maintenance use case delivered immediate ROI.
Common Pitfalls and How to Mitigate Them
Even with a solid plan, challenges can arise. Being aware of them is the first step towards avoiding them.
- Pitfall: Lack of Buy-In. If leadership and shopfloor staff do not understand the "why", they will not support the change.
- Mitigation: Start with a pilot programme to demonstrate clear ROI. Communicate wins and involve the team from day one.
- Pitfall: Analysis Paralysis. Getting lost in too much data without taking action.
- Mitigation: Start simple. Focus on one or two key data points (e.g. vibration) for your most critical assets. Act on the data you have before expanding.
- Pitfall: Poor Data Quality. If sensor placement is incorrect or data is inconsistent, your predictions will be inaccurate.
- Mitigation: Work with experienced vendors to ensure proper sensor installation and data configuration. Regularly validate your data against physical inspections.




